Đây được ví như thời đại của công nghệ thông tin, với các khái niệm như học máy, trí tuệ nhân tạo (AI) được ra đời và sớm phát triển, có nhiều ứng dụng trong mọi lĩnh vực của đời sống xã hội. Nằm trong xu hướng đó, machine learning là một lĩnh vực đầy tiềm năng, và biết càng sớm về nó bạn sẽ có càng nhiều lợi thế. Cùng tìm hiểu Machine Learning (học máy) là gì, các phương pháp học cơ bản và các thuật toán phổ biến nhất hiện nay thông qua bài viết dưới đây nhé.

Tóm Tắt Bài Viết
Học máy (Machine learning) là một lĩnh vực thuộc trí tuệ nhân tạo (AI) và khoa học máy tính, tập trung vào việc sử dụng dữ liệu và thuật toán để mô phỏng hành động của con người và từ từ nâng cao độ chính xác.
Học máy cũng là một thành phần quan trọng trong lĩnh vực khoa học dữ liệu đang phát triển. Bằng cách sử dụng các phương pháp thống kê, các thuật toán được đào tạo để thực hiện phân loại hoặc dự đoán và khám phá thông tin chi tiết từ các dự án khai thác dữ liệu.
Thông qua việc sử dụng thông tin chi tiết thu được, học máy có thể hỗ trợ trong việc đưa ra quyết định cho các ứng dụng và doanh nghiệp, góp phần quan trọng vào sự tăng trưởng. Với sự gia tăng liên tục của dữ liệu lớn, nhu cầu mở rộng và phát triển đòi hỏi sự tăng cường trong việc tuyển dụng các nhà khoa học dữ liệu. Họ sẽ được yêu cầu giúp xác định các câu hỏi kinh doanh có liên quan nhất và thu thập dữ liệu để trả lời chúng.
Các bài toán trong học máy thường được chia thành hai loại: dự đoán (prediction) và phân loại (classification). Các bài toán dự đoán thường liên quan đến việc dự đoán giá nhà, giá xe, vv, trong khi các bài toán phân loại thường liên quan đến việc nhận diện chữ viết tay, đồ vật, vv.
Supervised learning, còn được gọi là máy học có giám sát, là một phương pháp trong lĩnh vực học máy. Nó được xác định bằng cách sử dụng các tập dữ liệu được gắn nhãn để huấn luyện các thuật toán nhằm phân loại dữ liệu hoặc dự đoán kết quả một cách chính xác.
Trong quá trình huấn luyện, khi dữ liệu đầu vào được đưa vào mô hình, mô hình sẽ điều chỉnh các trọng số để phù hợp. Quá trình này thường đi kèm với việc sử dụng phương pháp xác nhận chéo để đảm bảo rằng mô hình không bị quá khớp hoặc thiếu thông tin.
Học máy có giám sát giúp các tổ chức giải quyết nhiều vấn đề trong thế giới thực trên quy mô lớn, ví dụ như phân loại thư rác trong hộp thư đến cá nhân.
Các phương pháp phổ biến được sử dụng trong học máy có giám sát bao gồm: hồi quy logistic, mạng neural, hồi quy tuyến tính, naive Bayes, rừng ngẫu nhiên và máy vector hỗ trợ (SVM).
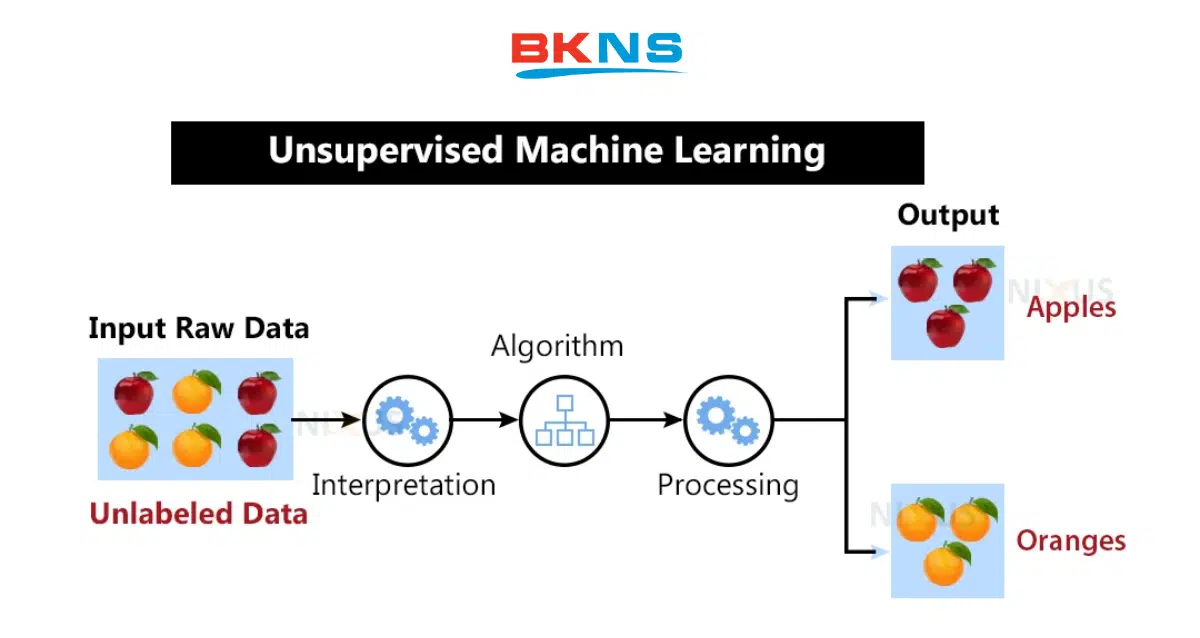
Unsupervised machine learning, còn được gọi là học máy không giám sát, là một phương pháp sử dụng các thuật toán máy học để phân tích và phân cụm các tập dữ liệu không được gắn nhãn.
Các thuật toán này có khả năng tự động phát hiện các mẫu hoặc nhóm dữ liệu ẩn mà không cần sự can thiệp của con người. Phương pháp này có thể tìm ra sự tương đồng và khác biệt trong thông tin, làm cho nó rất hữu ích trong việc khám phá dữ liệu, chiến lược bán chéo (cross-sell), phân khúc khách hàng, cũng như nhận dạng hình ảnh và mẫu.
Unsupervised machine learning cũng được sử dụng để giảm số lượng đặc trưng trong một mô hình thông qua quá trình giảm kích thước. Phân tích thành phần chính (PCA) và phân tích giá trị đơn lẻ (SVD) là hai phương pháp phổ biến được sử dụng cho mục đích này.
Các thuật toán khác được sử dụng trong học máy không giám sát bao gồm: phân cụm k-means, mạng neural và các phương pháp phân cụm xác suất.
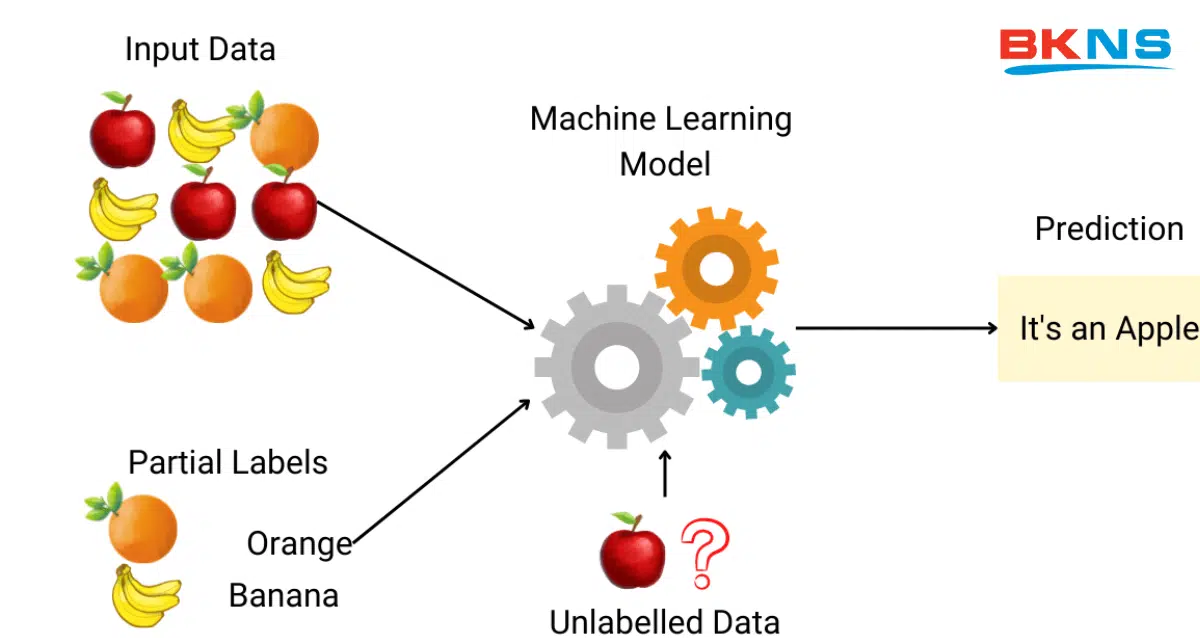
Học máy bán giám sát (Semi-supervised learning) cung cấp một phương pháp hiệu quả giữa học máy có giám sát và không giám sát. Trong quá trình huấn luyện, nó sử dụng một tập dữ liệu có nhãn nhỏ hơn để hướng dẫn trong việc phân loại và trích xuất đặc trưng từ một tập dữ liệu lớn hơn không có nhãn.
Phương pháp Học máy bán giám sát có thể giải quyết vấn đề khi không có đủ dữ liệu được gắn nhãn cho thuật toán học có giám sát. Nó cũng hữu ích khi việc gắn nhãn cho dữ liệu đòi hỏi chi phí và công sức lớn.
Học máy là một nhánh của trí tuệ nhân tạo (AI).
Trước khi bạn bắt đầu suy nghĩ về cách giải quyết vấn đề với machine learning, hãy dành một chút thời gian để suy nghĩ về vấn đề bạn đang cố gắng giải quyết. Hãy tự hỏi mình những câu hỏi sau đây:
Bạn phải có quyền truy cập vào một tập hợp lớn dữ liệu đào tạo bao gồm thuộc tính (được gọi là một tính năng trong machine learning) mà bạn muốn để có thể suy luận (dự đoán) dựa trên các tính năng khác.
Phát triển mô hình của bạn bằng cách sử dụng các kỹ thuật machine learning đã thiết lập hoặc bằng cách xác định các hoạt động và phương pháp tiếp cận mới.
Bắt đầu học bằng cách làm việc thông qua hướng dẫn của TensorFlow. Bạn cũng có thể làm theo tài liệu scikit-learning hoặc tài liệu XGBoost để tạo mô hình của mình. Sau đó, kiểm tra một số mẫu mã được thiết kế để hoạt động với Nền tảng AI .
Đến bước này, bạn cần bước huấn luyện cho mô hình của mình, có thể hiểu là giúp nó học trên dữ liệu mà bạn đã thu thập và xử lý ở hai bước đầu tiên của quy trình.
Sau khi đã huấn luyện xong, bạn cần đứng trên nhiều góc độ khác nhau để đánh giá mô hình đó, tùy vào từng góc độ mà mô kết quả đánh giá tốt hay không tốt sẽ có sự khác nhau. Với những mô hình được đánh giá đạt trên 80% sẽ được cho là tốt.
Bước cuối cùng trong quy trình machine learning chính là cải thiện. Sau khi đã thực hiện xong việc đánh giá mô hình, các mô hình đạt độ chính xác không tốt sẽ được đào tạo lại. Quá trình đào tạo lại sẽ bắt đầu từ bước 3 cho đến khi đạt độ chính xác cao đúng như kỳ vọng của bạn. Thông thường thời gian của 3 bước cuối cùng sẽ rơi vào khoảng 30% tổng thời gian thực hiện mô hình.
Một số ứng dụng thực tế của learning machine như:
Một số thông tin hữu ích về machine learning là gì đã được chia sẻ chi tiết đến bạn trong bài viết trên. Hy vọng thông qua bài bài viết trên của chúng mình, bạn sẽ hiểu rõ hơn về học máy là gì.
Có thể nói rằng lĩnh vực học máy là lĩnh vực vô cùng lớn với rất nhiều khái niệm và kiến thức liên quan. Nắm vững được lý thuyết căn bản sẽ giúp ích được cho bạn những công việc liên quan về sau.
Theo dõi BKNS để xem thêm nhiều thông tin hữu ích khác nhé.
> Đọc thêm các bài viết hữu ích khác:
AI là gì ? Ứng dụng và mặt trái của trí tuệ nhân tạo AI hiện nay

 Hosting Free
Hosting Free